



වර්තමාන තාක්ෂණික ලෝකයේ බොහෝ දෙනෙක් කරන්නේ වෙනත් සමාගමක API එකක් ලබාගෙන, ඒ මත සරල Wrapper එකක් නිර්මාණය කර එය තමන්ගේම නිෂ්පාදනයක් ලෙස හැඳින්වීමයි, නමුත් ක්ෂේත්රයේ සිටින ඉහළම මට්ටමේ AI ඉංජිනේරුවන් කරන්නේ තමන් සතු දත්තවලට ගැළපෙන ආකාරයට Open-source මොඩල් එකක් තෝරාගෙන, එය Fine-tune කර සැබෑ ප්රශ්න විසඳිය හැකි පද්ධති නිර්මාණය කිරීමයි, Prompt Engineering සහ Systems Architecture අතර පවතින වැටුප් පරතරය ඉතා විශාලයි, මෙම ලිපියෙන් සාකච්ඡා කරන්නේ සංකීර්ණ විද්යාත්මක වචන වෙනුවට, සරල එදිනෙදා උදාහරණ භාවිත කරමින් AI මොඩල් එකක් මුල සිටම Fine-tune කර පද්ධතියකට ඇතුළත් කරන ආකාරය පිළිබඳවයි,
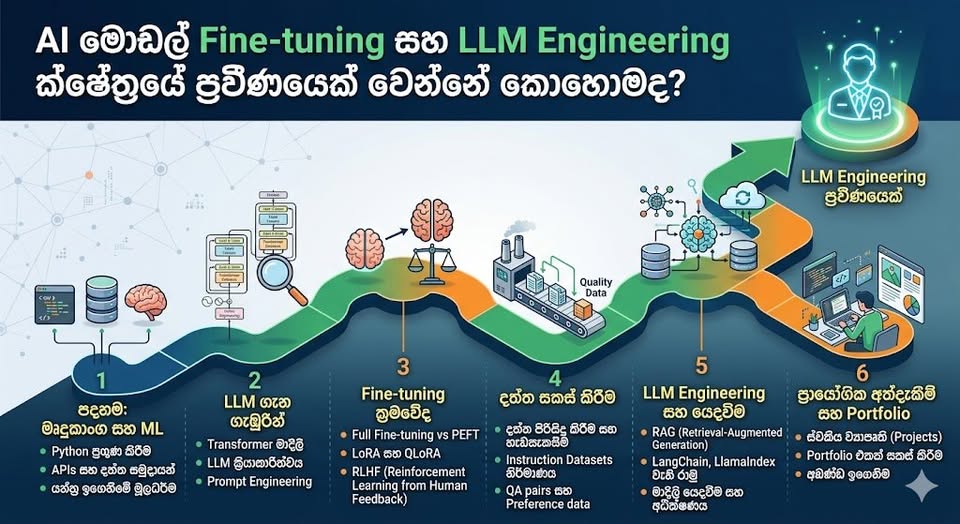
සාමාන්ය ක්රම සහ ප්රවීණ ක්රම අතර වෙනස
බොහෝ දෙනෙක් කරන්නේ ප්රධාන පෙළේ AI සමාගම්වලට මාසිකව විශාල මුදලක් ගෙවමින්, තමන්ගේ රහසිගත දත්ත වෙනත් සේවාදායකයන් වෙත ලබා දීමයි, නමුත් දක්ෂ AI ඉංජිනේරුවන් කරන්නේ Llama 3, Mistral, හෝ Qwen වැනි Open-source මොඩල් එකක් ලබාගෙන, Unsloth හෝ Axolotl වැනි මෙවලම් හරහා තමන්ගේම පරිගණකයක ඉතා අඩු වියදමකින් Fine-tune කර, 100% ක් ආරක්ෂිත සහ බලවත් AI පද්ධතියක් සාදාගැනීමයි, මේ සඳහා පයිතන් භාෂාව, Hugging Face, Ollama, vLLM, සහ PyTorch වැනි විවෘත මෙවලම් භාවිත කළ හැකියි,
පියවරෙන් පියවර ක්රියාත්මක වන ප්රධාන අදියර 5
මෙම විෂය කොටස් පහකට බෙදා පහසුවෙන් තේරුම් ගත හැකියි,
පළමු අදියර: මූලික අත්තිවාරම
AI මොඩල් එකක් ඇතුළත සිදුවන ක්රියාවලිය වටහා නොගෙන Fine-tune කිරීම අපහසුයි, LLM එකක් යනු වචන දෙස බලා ඊළඟට පැමිණිය යුතු වඩාත්ම ගැළපෙන වචනය කුමක්දැයි අනුමාන කරන ගණිතමය පද්ධතියකි, Parameters යනු මෙම මොඩල් එක ඇතුළත ඇති බිලියන ගණනක ගණිතමය අගයන් හෝ ලකුණුයි, මෙම අගයන් නිවැරදිව සකස් කිරීම පුහුණු කිරීම හෙවත් Training ලෙස හඳුන්වයි,
AI එක වචන කෙළින්ම කියවන්නේ නැත, එය වචන කොටස් හෙවත් Tokens වලට වෙන් කරයි, මෙම කොටස් ඉලක්කම් ලැයිස්තුවකට හැරුණු විට ඒවා Embeddings ලෙස හඳුන්වයි, මෙය වචනවල තේරුම අනුව හැදෙන සිතියමක් වැනියි, Attention Mechanism එකෙන් කරන්නේ වාක්යයක ඇති වචන එකිනෙක දෙස බලා, ඒ වෙලාවේ වැදගත්ම වචනය කුමක්දැයි වටහා ගැනීමයි, උදාහරණයක් ලෙස ඇපල් යන වචනය පළතුරක්ද නැතහොත් සමාගමක්ද යන්න හඳුනාගන්නේ වටපිටාවේ ඇති අනෙක් වචන දෙස බැලීමෙනි, මොඩල් එකකට දත්ත දී උගන්වන ක්රියාවලිය Training වන අතර, ඉගෙනගත් මොඩල් එකෙන් ප්රශ්නයක් අහලා උත්තරයක් ලබාගැනීම Inference ලෙස හඳුන්වයි,
- කෙටි සාරාංශය: LLMs යනු Transformers ව්යුහය මත හැදුණු, ඊළඟ වචනය අනුමාන කරන ගණිතමය පද්ධති වේ,
- මනෝභාවය: AI එකක් යනු ලෝකයේ ඇති සෑම පොතක්ම කියවා ඇති, නමුත් වචන අතර පවතින ගණිතමය දුර පමණක් තේරෙන දක්ෂ අනුමානකරුවෙකි,
- මඟහැරිය යුතු වැරදි: AI එකට මනුෂ්යයෙක් වැනි හැඟීම් ඇති බව සිතීම වැරදියි, එය ක්රියාත්මක වන්නේ පිරිසිදු ගණිතය මත පමණි,
- සරල ප්රොජෙක්ට් එකක්: Hugging Face ලිබ්රරිය භාවිත කර සරල පයිතන් කෝඩ් එකකින් මොඩල් එකක Tokenizer එක ක්රියාත්මක කර ඔයාගේ නම කොටස් කීයකට කැඩෙනවාද කියා පරීක්ෂා කරන්න,
දෙවැනි අදියර: දත්ත සකස් කිරීම
Fine-tuning වල සාර්ථකත්වය තීරණය වන්නේ 90% ක්ම ඔබ ලබාදෙන දත්තවල ගුණාත්මකභාවය මතයි, මොඩල් එකක් සාමාන්යයෙන් පොත් කියෙව්වාම කරන්නේ දිගු වැල්වටාරම් ලිවීමයි, අපට අවශ්ය ආකාරයට ප්රශ්නයක් ඇසූ විට කෙටි පිළිතුරක් දෙන රටාව උගන්වන්න Supervised Fine-Tuning හෙවත් SFT පාවිච්චි කරයි,
ඔබේ සමාගම සතු වෛද්ය හෝ නීතිමය දත්ත විශාල ප්රමාණයක් කෙළින්ම මොඩල් එකට මතක තබා ගැනීමට සැලැස්වීම Continued Pretraining ලෙස හඳුන්වයි, දත්තවල ඇති අකුරු වැරදි සහ අනවශ්ය කොටස් ඉවත් කිරීම දත්ත පිරිසිදු කිරීමයි, වර්තමානයේ බොහෝ විට කරන්නේ GPT-4 වැනි ලොකු මොඩල් එකක් ලව්වා අපට අවශ්ය ක්ෂේත්රයට අදාළව ප්රශ්න උත්තර දහස් ගණනක් සාදාගැනීමයි, ඒවා Synthetic Datasets ලෙස හඳුන්වයි,
- කෙටි සාරාංශය: මොඩල් එකක හැසිරීම වෙනස් කිරීමට SFT දත්ත අවශ්ය වන අතර, අලුත් ක්ෂේත්රයක දැනුම ලබාදීමට Continued Pretraining අවශ්ය වේ,
- මනෝභාවය: Continued Pretraining යනු වෛද්ය ශිෂ්යයෙක් පෙළපොත් කියවීමයි, SFT යනු ඒ ශිෂ්යයා විභාග ප්රශ්න පත්රවලට උත්තර ලියන්න පුරුදු වීමයි,
- මඟහැරිය යුතු වැරදි: අපැහැදිලි දත්ත ඇතුළත් කළහොත් ලැබෙන ප්රතිඵලයද වැරදි සහගත වේ,
- සරල ප්රොජෙක්ට් එකක්: JSONL ආකාරයට ඔබේ ව්යාපාරයේ නිතර අසන ප්රශ්න 20ක් එකතු කර සරල SFT දත්ත ගොනුවක් ඔබම නිර්මාණය කරන්න,
තුන්වැනි අදියර: උසස් Fine-Tuning ක්රම
මොඩල් එකක ඇති බිලියන ගණනක Parameters ඔක්කොම පුහුණු කිරීමට ගියහොත් අධික වියදමක් සහ ලොකු සර්වර්ස් අවශ්ය වේ, LoRA ක්රමවේදයෙන් කරන්නේ මුල් මොඩල් එකේ අගයන් වෙනස් නොකර තබා, ඒ මත ඉතා කුඩා ගණිතමය ස්ථරයක් පමණක් එකතු කර එය පමණක් පුහුණු කිරීමයි,
මෙම ක්රමය තවත් ලාභදායී කිරීමට මුල් මොඩල් එකේ බර 4-bit දක්වා අඩු කර, රැම් එක ඉතිරි කරගෙන LoRA ස්ථර පුහුණු කිරීම QLoRA ලෙස හඳුන්වයි, මේ නිසා සාමාන්ය Gaming ලැප්ටොප් එකක වුවද මොඩල් එකක් Fine-tune කළ හැකියි, මොඩල් එක පුහුණු කළ පසු එය වඩාත් සුදුසු පිළිතුරු දීමට හුරු කිරීම සඳහා DPO ක්රමය පාවිච්චි කරයි, එහිදී මොඩල් එකට හොඳ පිළිතුර සහ නරක පිළිතුර පෙන්වා හොඳ පිළිතුර දීමට හුරු කරවයි,
- කෙටි සාරාංශය: LoRA සහ QLoRA මඟින් වියදම සහ රැම් භාවිතය 90% කින් අඩු කරන අතර, DPO මඟින් මිනිසුන් කැමති ආකාරයට මොඩල් එක සකස් කරයි,
- මනෝභාවය: මුළු කාමරයම පාට කරනවා වෙනුවට, බිත්තියේ ඇති කුඩා රාමුවක් පමණක් තෝරා පාට කරනවා වැනි වැඩක් තමයි LoRA කියන්නේ,
- මඟහැරිය යුතු වැරදි: වැදගත්කම ඕනෑවට වඩා වැඩි කළහොත් මොඩල් එකට එහි පරණ මතකය සම්පූර්ණයෙන්ම අමතක වී යා හැකියි,
- සරල ප්රොජෙක්ට් එකක්: Google Colab එකක් භාවිත කර Unsloth ලිබ්රරිය හරහා Llama-3 මොඩල් එකක් QLoRA මඟින් විනාඩි 10කින් Fine-tune කරන්න,
හතරවැනි අදියර: වේගය වැඩි කිරීම සහ ක්රියාත්මක කිරීම
මොඩල් එක පුහුණු කළ පසු එය පාරිභෝගිකයන්ට පාවිච්චි කිරීමට දීමේදී ඉතා වේගයෙන් පිළිතුරු ලැබිය යුතුයි, ලොකු මොඩල් එකක් සාමාන්ය පරිගණකයක ධාවනය කිරීමට එහි ප්රමාණය අඩු කර GGUF ආකාරයට සකස් කරයි,
AI එක පිළිතුරු දීමේදී කලින් ලියූ වචන නැවත නැවත කියවීම වැළැක්වීමට සහ ඒ මතකය රඳවා ගැනීමට KV Cache පාවිච්චි කරයි, Flash Attention මඟින් GPU එක ඇතුළේ සිදුවන ගණනය කිරීම් වේගවත් කරයි, සැබෑ ලෝකයේදී එකවර පාරිභෝගිකයන් විශාල ප්රමාණයක් පැමිණි විට ඔවුන් සැමටම එකවර පිළිතුරු දීමට vLLM වැනි සර්වර්ස් පාවිච්චි කරයි, සාමාන්ය පරීක්ෂණ වැඩ සඳහා Ollama පාවිච්චි කළ හැකියි,
- කෙටි සාරාංශය: Quantization මඟින් මොඩල් එකේ ප්රමාණය අඩු කරන අතර vLLM සහ Flash Attention මඟින් පිළිතුරු දෙන වේගය උපරිම කරයි,
- මනෝභාවය: KV Cache කියන්නේ ගණන් හදද්දී හැම පියවරකම උත්තරය කොළයක පැත්තකින් ලියා තබාගන්නවා වැනි වැඩකි, එවිට නැවත මුල සිට සෑදීමට අවශ්ය නොවේ,
- මඟහැරිය යුතු වැරදි: පද්ධතිය සජීවීව ක්රියාත්මක කිරීමේදී සාමාන්ය පයිප්ලයින් පාවිච්චි කිරීමෙන් වේගය අඩාල වේ, ඒ සඳහා vLLM වැනි සර්වර් එකක් අනිවාර්යයෙන්ම පාවිච්චි කළ යුතුයි,
- සරල ප්රොජෙක්ට් එකක්: Ollama හෝ llama.cpp පාවිච්චි කර ඔබ සකස් කළ මොඩල් එක GGUF වලට හරවා ඔබේම පරිගණකයේ local API එකක් ලෙස ධාවනය කරන්න,
පස්වැනි අදියර: සැබෑ ලෝකයේ පද්ධති සැකසීම
Fine-tuning මඟින් කරන්නේ මොඩල් එකට හැසිරීමක් ඉගැන්වීම පමණි, එයට නිරන්තරයෙන් අලුත් දත්ත ලබාදීමට අපි වෙනත් ක්රම පාවිච්චි කරමු, මොඩල් එකට සැමවිටම අලුත්ම තොරතුරු දීමට, ප්රශ්නයක් පැමිණි විට Vector Database එකකට ගොස් අදාළ ලියකියවිලි සොයාගෙන, එය මොඩල් එකට පසුබිම් විස්තර ලෙස දෙන ක්රමය RAG ලෙස හඳුන්වයි,
AI එකකට තනියම වැඩ කිරීමට බලය දීම Agents ලෙස හඳුන්වයි, උදාහරණයක් ලෙස අද කාලගුණය පරීක්ෂා කර ඊමේල් එකක් යවන්න කී විට, AI එක තනියම අදාළ සේවාවලට කෝල් කර දත්ත ලබාගෙන ඊමේල් එකක් යවයි, අපේ මොඩල් එක ඇත්තටම දක්ෂද කියා මැනීමට MMLU වැනි ක්රම පාවිච්චි කර එහි ගුණාත්මකභාවය සහ වේගය මනිනු ලබයි,
- කෙටි සාරාංශය: RAG මඟින් මොඩල් එකට බාහිර තොරතුරු පෙනෙන අතර, Agents මඟින් මොඩල් එකට සැබෑ ලෝකයේ වැඩ කිරීමට හැකියාව ලැබෙයි,
- මනෝභාවය: Fine-tuning කියන්නේ දක්ෂ වෛද්යවරයෙක් පුහුණු කිරීමයි, RAG කියන්නේ ඒ වෛද්යවරයාට ලෙඩාගේ වෛද්ය වාර්තා කියවන්න දීමයි, මේ දෙකම එකතු වූ විට හොඳම ප්රතිඵල ලැබෙයි,
- මඟහැරිය යුතු වැරදි: ඔබේ දත්ත නිතරම වෙනස් වන ඒවා නම් (උදාහරණයක් ලෙස බඩු මිල ලැයිස්තුවක්), ඒ සඳහා Fine-tuning ගැළපෙන්නේ නැත, ඒ සඳහා RAG පාවිච්චි කළ යුතුයි,
- සරල ප්රොජෙක්ට් එකක්: PydanticAI පාවිච්චි කර, ඔබ සෑදූ මොඩල් එකට කාලගුණ API එකක් සම්බන්ධ කර තනියම දත්ත ගත හැකි සරල AI Agent කෙනෙක් නිර්මාණය කරන්න,
ආර්ථික වාසිය සහ අනාගතය
ප්රධාන සමාගමක API එකක් දිගින් දිගටම පාවිච්චි කිරීමේදී මිලියනයක් ටෝකන්ස් සඳහා විශාල මුදලක් වැය වේ, පාරිභෝගිකයන් ලක්ෂයක් පමණ පැමිණි විට එම බිල ඉතා ඉහළ යයි, නමුත් Fine-tuned මොඩල් එකක් vLLM හරහා Run කළ විට ඔබට වැය වන්නේ එකම එක Cloud GPU වියදම පමණි, පාරිභෝගිකයන් කී දෙනෙක් පැමිණියත් වියදම ස්ථාවරව පවතියි, ව්යාපාරවලට තමන්ගේ දත්ත ආරක්ෂා කරගැනීමට අවශ්ය නිසා, ඔවුන් මේ වගේ පෞද්ගලික AI පද්ධති සාදාගැනීමට විශාල මුදලක් ගෙවීමට සූදානම්,
නිකම්ම ChatGPT එකට ප්රොම්ප්ට් ඇතුළත් කරන අයව ඕනෑම කෙනෙක්ට ප්රතිස්ථාපනය කළ හැකියි, නමුත් Open-source මොඩල් එකක් ලබාගෙන, දත්ත පිරිසිදු කර, LoRA හෝ QLoRA හරහා පුහුණු කර, සර්වර් එකක වේගයෙන් ධාවනය කරන්න දන්නා සැබෑ AI පද්ධති නිර්මාණකරුවෙක්ව කිසිදා ඉවත් කළ නොහැකියි, අදම මෙවැනි පද්ධතියක් පරීක්ෂා කර බලා ඔබේ පළමු මොඩල් එක Fine-tune කිරීමට පියවර ගන්න, එය ඔබේ අනාගත වෘත්තීය ජීවිතයට ඉතා හොඳ පදනමක් වේවි,
-Shalinda Jayasinghe-

